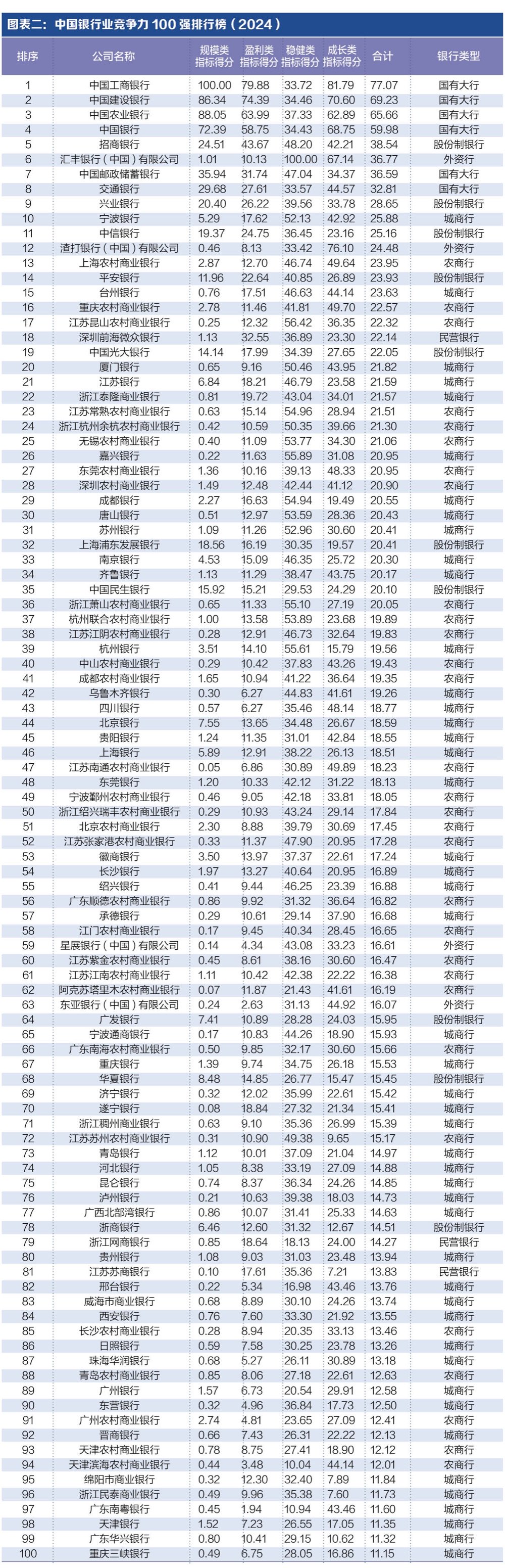
Facebook母公司Meta Platforms(META.US)表示,由于欧洲监管环境的不可预测性,将不会向欧盟客户提供其多模式人工智能模型Llama。
上个月,Meta 表示将推迟其人工智能助手 Meta AI 在欧洲的推出,因为它正在处理爱尔兰隐私监管机构关于使用 Facebook 和 Instagram 内容作为训练数据的请求。Meta 还看到倡导组织 NOYB 向 11 个欧洲国家提出投诉,指控该公司计划在未征求用户同意的情况下使用个人数据来训练其人工智能模型。
同样,苹果(AAPL.US)上个月指出,由于《数字市场法案》(DMA),它推迟了在欧盟发布其几项人工智能功能。DMA 是一部立法,建立了一套客观标准,将大型在线平台认定为“看门人”,并确保它们在网上公平行事,并留有可争议的空间。
Meta 打算将新的多模式模型融入多种产品中,包括智能手机和该公司的 Meta Ray-Ban 智能眼镜,该模型能够对视频、音频、图像和文本进行推理。

Meta 指出,欧洲企业和机构几乎肯定会失败,因为他们无法获得最新、最好的开放模式。
该公司补充称,与世界其他地区相比,欧洲监管机构花了更长的时间来确定法律要求。
Meta 补充说,欧盟和英国的《通用数据保护条例》(GDPR)几乎相同,但该公司仍继续在英国开展业务,因为英国机构对发现的问题给出了明确的反馈。
因此,据知情人士透露,这并不是法律的问题,而是欧盟不可预测的法律应用方式的问题。
Meta 还打算很快推出一款更大的纯文本版 Llama 3 模型。据该公司称,这款模型将面向欧盟客户和公司推出。
训练人工智能模型需要大量数据,欧盟的公司必须遵守欧盟关于如何收集和处理用户个人数据的规定。
Meta 在 5 月份宣布,它打算使用 Facebook 和 Instagram 用户的公开帖子来训练未来的模型。该公司表示,它在宣布其人工智能计划的几个月前就向欧盟监管机构通报了情况,并处理了他们的反馈,但反馈很少。

今年 6 月,爱尔兰数据保护委员会(DPC)代表欧洲数据保护机构要求Meta推迟使用 Facebook 和 Instagram 上的公开内容训练其大型语言模型(LLM)。
Meta 补充说,在推出后,欧盟监管机构要求其暂停,但没有明确表示担忧;并向其提出了 270 多个详细问题。该公司指出,它将继续与爱尔兰 DPC 接触,但欧洲监管环境的现实是,它尚不清楚何时可以开始培训。
然而,该公司指出,对欧盟数据的训练对于确保其产品正确反映该地区的术语和文化至关重要。Meta 表示,该公司的模型对欧洲公民和企业来说不会那么好,而且会更加美国化,而不是全球化。
Meta 此前曾表示,它正在效仿其他公司的做法,例如 Alphabet 旗下的谷歌和微软支持的 OpenAI,这两家公司都已使用来自欧洲人的数据来训练人工智能。